Pipas - Stream
For streaming data ingest into GCP we’are using the following architecture:
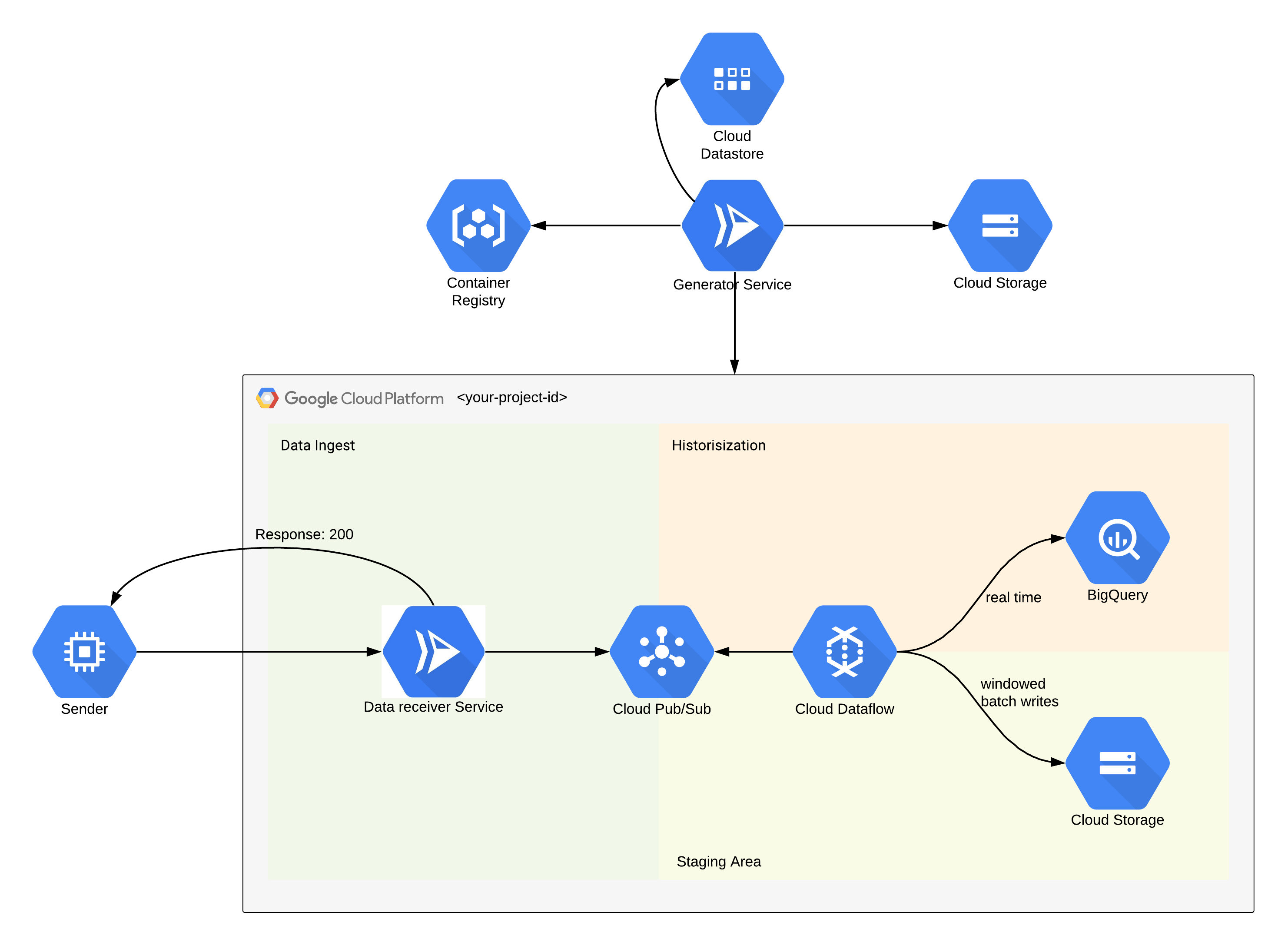
Our pipas-generator-service creates a ready-to-use GCP environment for streaming your data into BigQuery within a few seconds.
All components in detail:
-
Sender: The sender (i. e. a data source system like the search bar in a webshop) only have to push data to a Google Cloud Run Service via a standard REST API call. If the json body of the POST request isn’t broken, the sender immediately gets a 200 back.
-
Data Receiver Service: The only job of this service is to add some metadata information to the received json message and push it to a Google Cloud Pub/Sub Topic. There are several reasons why it is better to have this service than pushing directly on Pub/Sub. First, with Cloud Run you can easily set a custom DNS. Furthermore its decouples the sender and Pub/Sub. That means, if something changes in the background, the sender doesn’t care.
-
Cloud Pub/Sub: As mentioned above, the data receiver pushes data to a GCP Pub/Sub Topic. One subscriber for the topic is our Google Cloud Dataflow pipeline (see below) for historization of the data. But if you have an use-case, which needs this data in real-time (i. e. real-time recommendations on a website), you can easily create a subscription and consume the data as soon as the gets pushed from the sender, independent from the historization subscription.
-
Cloud Dataflow: With Cloud Dataflow takes over the actual historization part of the sended json messages. Dataflow consumes the data via the mentioned Pub/Sub historization subscription, deduplicate messages and streams the data into a Google Cloud BigQuery table and a Google Cloud Storage Bucket. Dataflow is serverless and autoscaling, so you don’t have to care about your data ingest on peak hours, Google does this for you. Furthermore, processing time of data through the flow Pub/Sub -> Dataflow -> BigQuery is extremely fast.
-
Cloud Storage: We are also saving the Pub/Sub raw messages in our Dataflow pipeline on a Google Cloud Storage Bucket. This will be archieved via windowed batches writes. That means, the dataflow pipeline collects n messages (n depends on the adjusted deployment parameters) and save the n massages to a .arvo file into the Bucket. The reason why we are doing it this way is, that it’s more cost and storage effective than writing every single Pub/Sub message as a own file on a Bucket. But why do we even store the data on a Bucket when we are already streaming the data into a BigQuery? The answer for this question is quite simple: Just to have a fallback if someone deletes the BigQuery table/dataset by mistake. We don’t want to loose any kind of data.
-
BigQuery: Once data has arrived in BigQuery, you can easily query it and use it for analytical purposes.